Intelligent Request Cache
Monsta employs a system of intelligent instance request caching to optimize network monitoring, significantly reducing bandwidth consumption and computational resource usage both on the monitored device and on the server hosting Monsta. This mechanism operates by identifying and storing data from previously queried requests, avoiding the need for new requests for information that is already known.
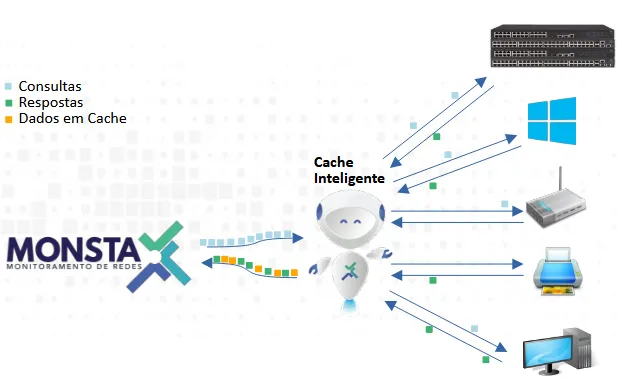
Technical Operation
Section titled “Technical Operation”The intelligent cache process can be detailed in the following steps:
- Request Interception: When a monitor initiates a request to obtain information from a network device (for example, port speed, total memory, list of instances, etc.), the request is first intercepted by the intelligent cache module.
- Instance Validation: Monsta uses a technique to validate whether the properties of the requested instance have been modified:
- When changes exist, the cache is marked as expired and a new query is performed;
- If no changes exist, the query will be directed to the cache.
- Cache Verification: Before forwarding the request to the monitored device, the cache module checks whether the requested instance already exists in its local cache repository. This verification is based on a unique identifier for each type of request and for each device.
- Cache Hit:
-
Individual queries: If the instance is found in the cache (cache hit) and is within its validity period, Monsta does not send the request to the device. Instead, the previously stored response is immediately returned to the requesting metric.
-
Walk: For queries that need to obtain information from part of the OID tree, such as the names of network interfaces via an snmpwalk, Monsta uses techniques that only revalidate the cache when there are changes in the positions of its elements. In this case the TTL (Time-to-Live) is not used.
These processes eliminate the need for network traffic and for the monitored devices to process the request, as well as saving Monsta server resources that would otherwise be spent on communication and response processing.
-
- Cache Miss: If the instance is not found in the cache (cache miss) or if its validity period has expired, the request is then sent to the monitored network device. After the device responds, the information is processed and, before being delivered to the requesting module, a copy is stored in the cache along with a new TTL. The TTL is configurable and determines how long the information is considered valid in the cache.
- TTL (Time-To-Live) Management: Each item stored in the cache has an associated TTL. This value defines the “lifespan” of the information in the cache. Once the TTL expires, the information is considered outdated and the next request for that information will result in a “cache miss”, forcing a new query to the device to ensure the most recent data is obtained. The TTL can be adjusted based on the criticality and update frequency of the information. To adjust it, access the Settings menu, Parameters and change its time in the variable inst.cache_ttl_secs (the default value is 10 seconds). Setting this value to “0” disables the cache for individual queries.
Technical Benefits
Section titled “Technical Benefits”- Reduced Load on the Monitored Device: Decreases the number of requests processed by network devices, freeing resources for their primary functions.
- Network Bandwidth Optimization: Minimizes monitoring traffic on the network, especially in environments with a large number of devices or low-bandwidth links.
- Monsta Server Resource Savings: Reduces CPU and memory consumption on the Monsta server, since many responses are delivered directly from the cache, avoiding the overhead of network communication.
- Improved Response Latency: Requests that result in a “cache hit” are answered instantly, improving the user experience and the speed of data visualization.
Monsta’s intelligent request cache is a fundamental component to ensure the system’s scalability and efficiency, allowing monitoring of large and complex network infrastructures with optimized performance.